Line & Scatter Plots
Contents
Line & Scatter Plots#
This notebook introduces the methods of creating bar charts from our data, including some of the key concepts of our plotting package, matplotlib. Bar charts are useful for making comparisons between close data because we are very good at evaluating the size of rectangles.
Topics covered:
bar charts
styling charts (titles, labels, size, color, etc)
grouped bar charts
tacked bar charts
new
school_datapackage for custom code
To work on these examples we will use the demographics and ELA/Math test score data.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import scipy
from scipy.stats import pearsonr
from IPython.display import Markdown as md
from nycschools import schools, ui, exams
df = schools.load_school_demographics()
tests = exams.load_math_ela_long()
Scatter plots and correlations#
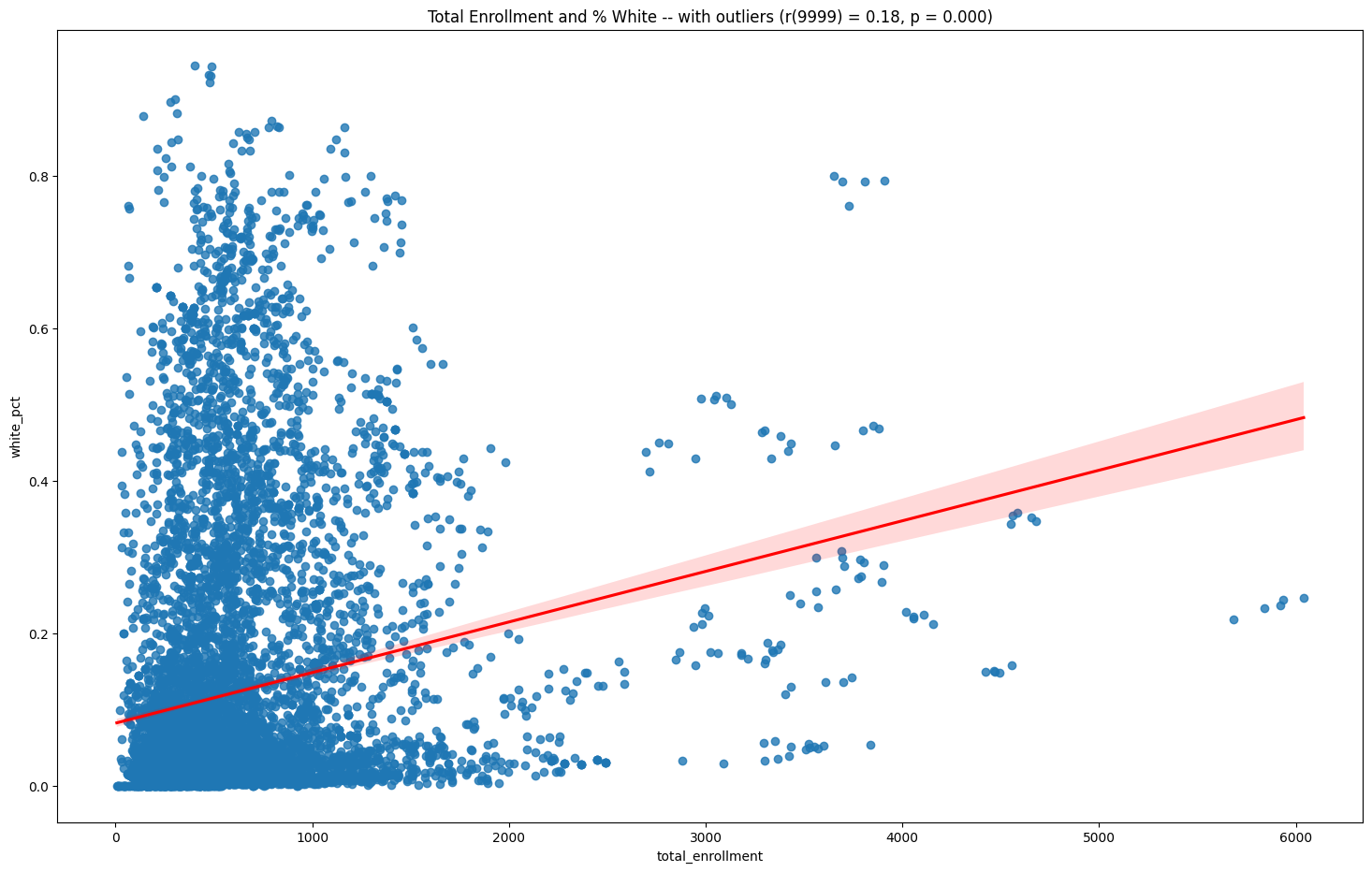
In the next section we’re going to see what demographic factors of schools impact student test scores on the NYS ELA exams, grades 3-8.
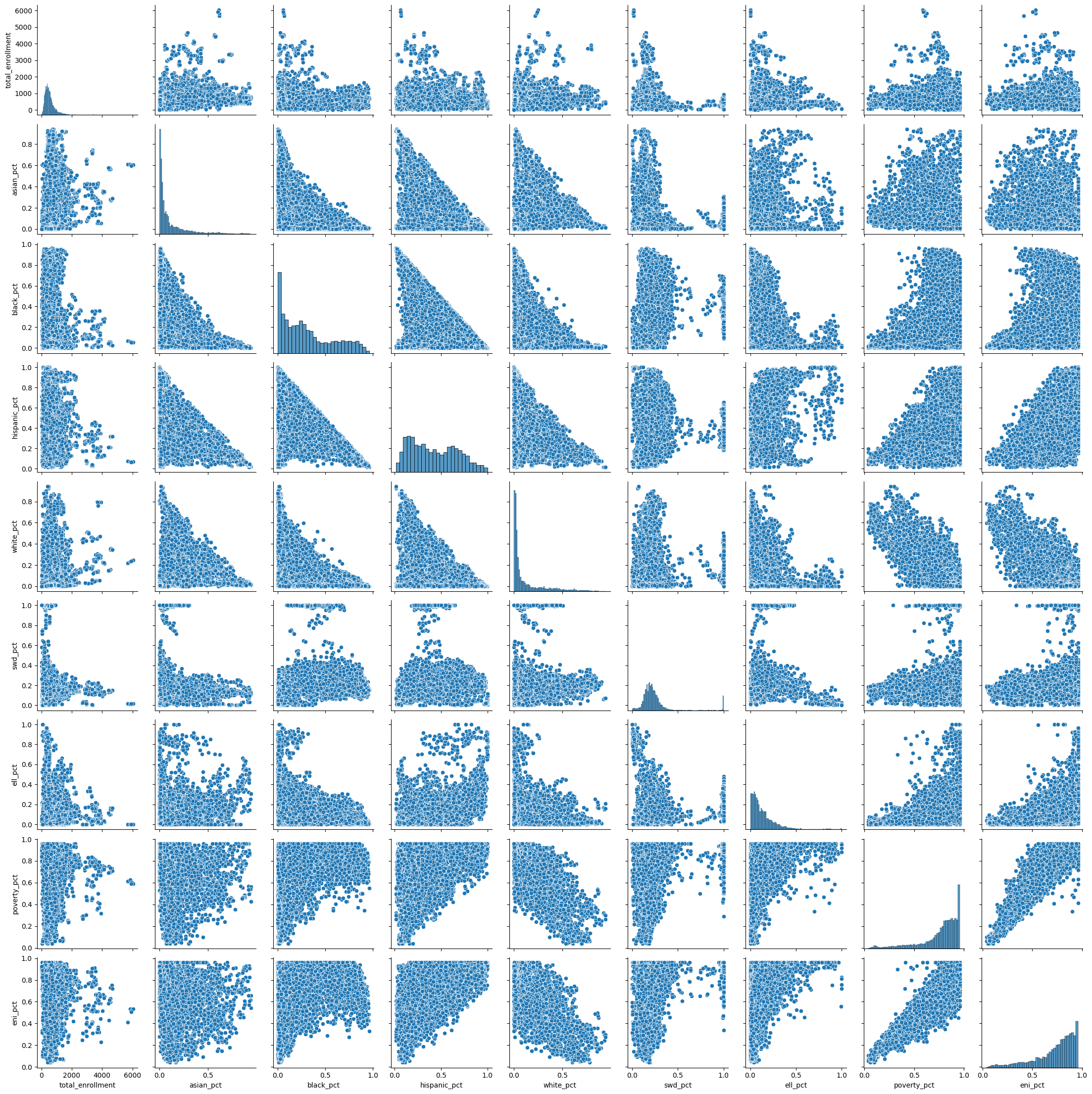
factors = ['total_enrollment', 'asian_pct', 'black_pct', 'hispanic_pct', 'white_pct', 'swd_pct', 'ell_pct', 'poverty_pct', 'eni_pct']
# create a table of the correlation matrix with a cool->warm color map
corr = df[factors].corr()
corr.style.background_gradient(cmap='coolwarm')
| total_enrollment | asian_pct | black_pct | hispanic_pct | white_pct | swd_pct | ell_pct | poverty_pct | eni_pct | |
|---|---|---|---|---|---|---|---|---|---|
| total_enrollment | 1.000000 | 0.350720 | -0.251269 | -0.095415 | 0.176726 | -0.187808 | -0.005513 | -0.149179 | -0.189138 |
| asian_pct | 0.350720 | 1.000000 | -0.450250 | -0.346040 | 0.191238 | -0.213357 | 0.151237 | -0.258741 | -0.307453 |
| black_pct | -0.251269 | -0.450250 | 1.000000 | -0.428332 | -0.456705 | 0.125320 | -0.356624 | 0.303223 | 0.250974 |
| hispanic_pct | -0.095415 | -0.346040 | -0.428332 | 1.000000 | -0.385142 | 0.077647 | 0.442527 | 0.465564 | 0.531882 |
| white_pct | 0.176726 | 0.191238 | -0.456705 | -0.385142 | 1.000000 | -0.080427 | -0.186733 | -0.790558 | -0.760384 |
| swd_pct | -0.187808 | -0.213357 | 0.125320 | 0.077647 | -0.080427 | 1.000000 | 0.031075 | 0.191904 | 0.266450 |
| ell_pct | -0.005513 | 0.151237 | -0.356624 | 0.442527 | -0.186733 | 0.031075 | 1.000000 | 0.346132 | 0.396029 |
| poverty_pct | -0.149179 | -0.258741 | 0.303223 | 0.465564 | -0.790558 | 0.191904 | 0.346132 | 1.000000 | 0.912243 |
| eni_pct | -0.189138 | -0.307453 | 0.250974 | 0.531882 | -0.760384 | 0.266450 | 0.396029 | 0.912243 | 1.000000 |
# scatter plot of all of the factors
sns.pairplot(df[factors], kind="scatter")
pass
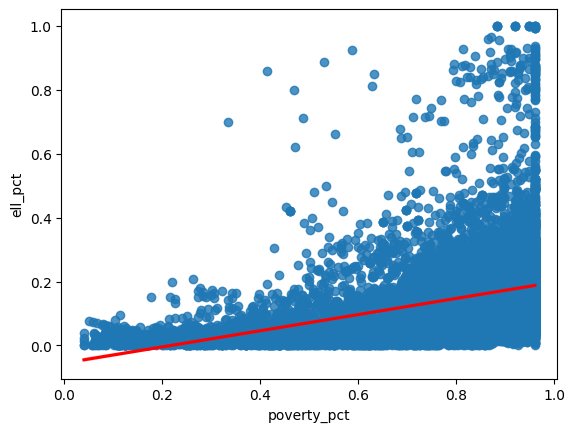
sns.regplot(x=df["poverty_pct"], y=df["ell_pct"], line_kws={"color": "red"} )
plt.show()
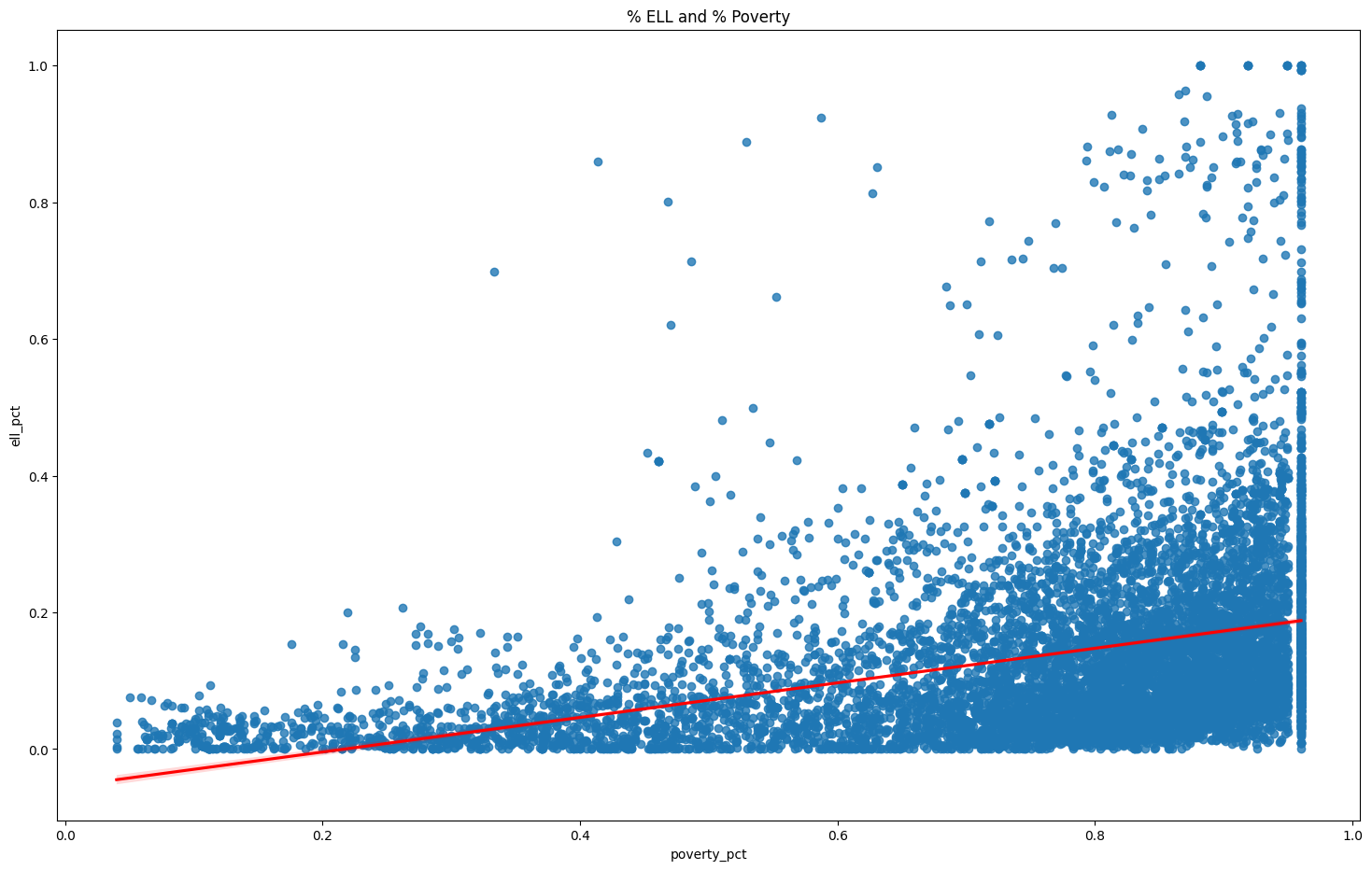
g = sns.regplot(x=df["poverty_pct"], y=df["ell_pct"], line_kws={"color": "red"} )
g.figure.set_size_inches(18, 11)
g.set(title="% ELL and % Poverty")
# show the correlation plot in jupyter
r, p = pearsonr(df['poverty_pct'], df['ell_pct'])
degs_f = len(df) - 2
report_r = f"""
**A Pearson's correlation coefficient** was computed to assess the linear relationship
between _% poverty_ and _% English Language Learners_ (ELL).
There was a positive correlation between the two variables, r({degs_f}) = {r:.2f}, p = {p:.3f}.
"""
display(md(report_r))
plt.show()
A Pearson's correlation coefficient was computed to assess the linear relationship between % poverty and % English Language Learners (ELL).
There was a positive correlation between the two variables, r(9999) = 0.35, p = 0.000.
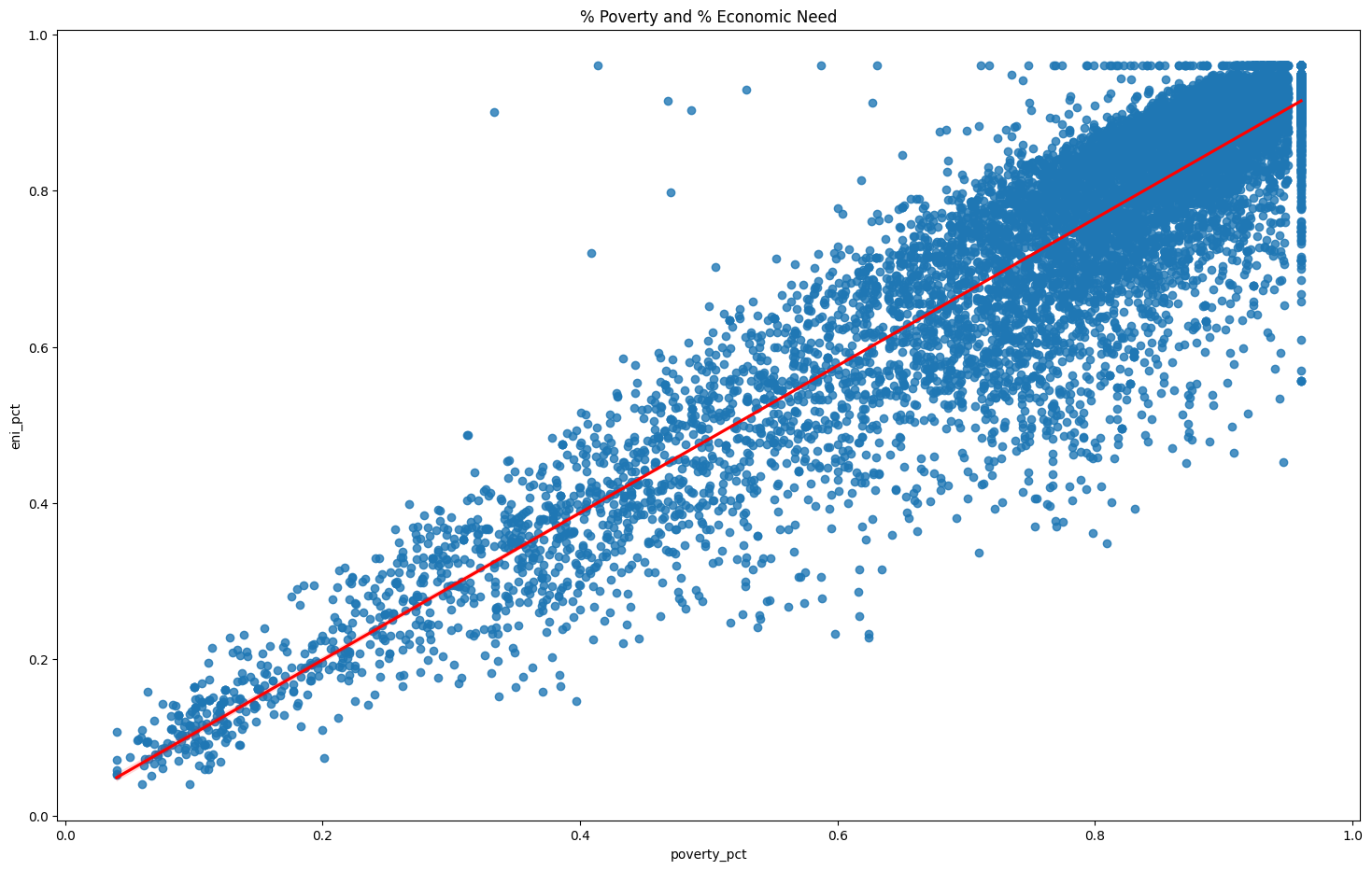
# plot highly correlated % poverty and economic need index -- both measures look at poverty in schools
g = sns.regplot(x=df["poverty_pct"], y=df["eni_pct"], line_kws={"color": "red"} )
g.figure.set_size_inches(18, 11)
g.set(title="% Poverty and % Economic Need")
plt.show()
Drop outliers#
For the next correlation, first we’ll drop the outliers by computing z-scores. Outliers can distort the results of our correlations.
outliers = df[["white_pct", "total_enrollment"]]
x = outliers["total_enrollment"]
y = outliers["white_pct"]
g = sns.regplot(x=x, y=y, line_kws={"color": "red"})
g.figure.set_size_inches(18, 11)
r, p = pearsonr(x, y)
# use the ui helper funciont fmt_pearson to report the r and p values from our correlation
g.set(title=f"Total Enrollment and % White -- with outliers (r({len(x)-2}) = {r:.2f}, p = {p:.3f})")
plt.show()
pass